A very core principle of building microservices is enabling teams to deliver at a constant incremental pace and not in a big bang or spasmodic approach. Teams must be trained and prepared for cogent disruption in adopting agile methodologies processes.
Microservices requires teams to follow the core principle of agile in working at a constant pace, which in turn enables teams to deliver at a constant pace.
DevOps and DataOps culture needs to be embedded into teams. Teams must be enabled to have greater control over their environment and make multiple releases into production with a fail fast and fail forward approach.
Don’t get into a situation where certain teams are more agile than others. This can lead to a lot of slow down, especially with cross-team communication and integration.
Containers should be a standard part of any agile infrastructure, especially when working on legacy platforms that require specific infrastructure and length installation. Build service containerization to take advantage of the flexibility, speed of deployment, configurability, and automation.
Do spend resources and time on the monolith and its improvement. Seldom, teams just start concentrating on building new-age technology solutions and hardly spend time understanding the legacy system. Without understanding the monolith, it’s hysterical to even attempt breaking it.
Microservice’s journey is all about gradually overhaul, every time you make a change you need to keep the system in a better state or the state that it was before.
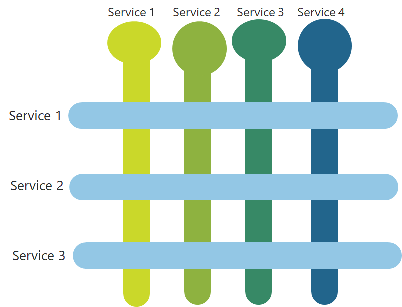
Moving out of Services can happen either Vertically or Horizontally. Clearly nail down those horizontal services that need to be common overall. Try to identify those vertical services and the best way typically are to migrate them by first moving the data, then the business logic and later the front end.
Always try to target the first step as is to create a macro service until the core services are demarcated. Once the demarcations are clear it is easy to further split into microservices.
In the beginning, the teams have less operational maturity, during this phase minimize the number of microservices and reduce the cognitive load.
The simplest of services, to begin with, in my experience are read-only applications. Especially, the ones that are business-centric and that change very often. This allowed us getting the business team’s confidence that the teams can move faster and deliver those features rapidly.
The team that I was part of initially were depending a lot on the monolith application. The services were deployed multiple times a day, whereas the monolith application was deployed once a week. The services should never wait for the monolith to be deployed.
Also, every time changes went into the monolith, it was always ensured that there were feature flags. This gave the developers the leeway to revert and test changes if in case hell broke loose.
Do not add a dependency to the monolithic platform. Ensure that the new services do not call the monolithic application directly and always access it via the anti-corruption layer.
Concluding Thoughts
A microservice journey is complex and seldom have organizations been successful. And if you have gone ahead and started that journey, do take intermittent checks on where you stand and correlate to where you started from.
If after building services you are in a situation where all developers congregate to fix production issues
if teams require several developers and take umpteen number of days to fix issues
If your applications have several hours of downtime
If your services cannot be tested as a single entity
If the teams fear to make changes to the code when adding new features
If you are reverting code and releases instead of failing fast or failing forward
If you are building services that access the same database
If the services and functionality is spread across multiple services and teams
If your applications take multiple teams and several people to deploy changes to production
If there are too many services depending on each other
If your teams are still writing and performing manual tests
If you are building services with hundred of Classes having hundreds of lines of code
If you have several services that have not been modified for several months
Maybe, you have ended up building another monolith.
Modularization is another indispensable prerequisite, to begin with when designing microservices. Without modules defined, I have seen teams building services in a wild goose chase fulfilling the anti-patterns of complex data interoperability across distributed systems, tightly coupling of services by maximizing dependencies, minimal composability and abstraction and the list goes on….
Uncle Bob once famously said
“Gather together the things that change for the same reasons. Separate those things that change for different reasons”.
It’s essentially an abstraction of concerns of business capabilities by understanding and defining the exact core services or modules of an application landscape. InIt’she same basic concept followed by designing any monolithic application.
Where teams fail to understand is that with an improper composition of core components or modules, all you are doing is shifting complexities to more gray areas. This is a whole reason why in the first place the monolithic application was designed to be a haphazardly structured application or otherwise famously defined as “Big Ball of Mud”.
“Deciphering the concern based modularization of an enterprise is an essential requisite to amalgamate the intricacies of the microservices system.”
In one of the microservices journeys, I was part of a team that wanted to jump-start creating services and in parallel define their core modules. In doing so they came across a situation where they had the same core source information in multiple systems and this resulted in a pretty complex data interoperability across multiple services. Fixing things at this point is tedious impacting several applications.
Also, another issue seen is the over creating of core services which is a mess. It will lead to several unnecessary layers. It just adds complications to the application landscape where every service is depending on the other without any realm of responsibility.
Get the core and sub-core concern components that are baselined at the earliest.
Domain-driven design (DDD) needs to be adopted to help choose domain boundaries or business context.
Applications need to be divided and conquered to identify the organic sized chunks of these components.
Core services by definition are services that mainly focus on persistence and are pure data-centric. Each isolated core services will be the future master of information and the discrete source of truth.
Once the core services are nailed down, detailing out the Peripheral and Composite services becomes much easier.
One major point of argument that I have come across in every team when building micro-services is to Use the existing code or rewrite the code?
When building new functionality the majority of the time it makes sense to rewrite capability and not the code. This may be time-consuming to build, but the monolithic platform already has a lot of redundant code.
By rewriting capability it gives an opportunity to improve the granularity of the service, revisit business functionality, and maintain a clean codebase.
Business and IT teams always spend a lot of money on solutions that are deemed to be the right way. But, many a time the only reason these extravagant solutions are running is because they are spending a lot of money on it.
One of the teams that I was part of the business spent a huge amount of licensing money every year on a proprietary solution and were hesitant to change.
However, the software was pretty tedious and it was very slow building functionalities. The team started with a POC and realized that in a few weeks they could build the same core functionalities with open-source software. They went ahead and did that and it opened up a surfeit of opportunities for the business team to improve upon.
Be rational in decision making and avoid sunk cost fallacy situation.
Stay practical in what needs to be rewritten and what needs to be reused. Sometimes the later may be a good choice as not everything in the monolith is a throwaway.
In another instance, one of the teams were struggling to re-architect complex business functionality and moving very slow. The business knew that this was going beyond the scheduled budget and time and did not yield many benefits, but they struggled to decide to dismantle the team.
It’s never too late to pull the plug when building services. In situations where certain core functionalities built don’t change much just reuse stuff. Maybe a good code review is what is required.
Once the initial approach is selected, the next challenge is defining teams and how to manage the key challenges to attain velocity and sizing within teams.
A socio-technical framework is being used more and more when building complex systems, especially those that deal with the principles of working in teams and agile environments where adaptability is the key. Below are a few common questions that the teams need to dwell upon and ask themselves?
How big a microservices application has to be? Should it be a Micro, Macro or even a Mini service?
How to keep in context without swapping out or referring documentation, or human intervention?
How to embrace changes in the application? How to build software that is faster time to market?
How to bring in a new person and develop without any wait times?
The concept of “Cognitive Load” is getting used quite often when sizing microservices. The concept has been borrowed from the psychological dictionary where the cognitive load refers to the information one keeps in the head without referring to something else. It’s a universal concept used for learning and to help maintain optimum load on the working entity. It can be defined as a temporary working memory like a Cache or Ram.
“Producing maintainable software depends on readable information be it code, modules, or documents, and readable information depends on controlling Cognitive Load.”
There are three types of Cognitive Loads defined
Intrinsic Load is related to the complexity of information that a team is paying attention to and processing. It’s bae skills and demands on specific tasks or technology that one is grasping and the difficulty of learning the task itself. In building microservices this can be the initial load that is required to create an end to end service.
Extraneous load is completely unrelated to the learning task. These are all the negative distractions and additional effort imposed on the team or system.
Germane load is the mental processing effort and is directly going towards supporting of development of schema and long-term memory. In building software, it is the repeated decorative knowledge and conglomeration on how this thing to play in a more complicated system.
Intrinsic and Germane load are considered “good” and Extrinsic is “bad”.
Always in teams try to find and offload those extrinsic loads that affect the teams.
The extrinsic loads identified in the teams that I was part of included environmental issues, complicated subsystems, unnecessary complex or business Logic, complex code, misfit teams, team meetings, etc….
Many a time, it could also be as simple as spending time on unnecessary documentation that no one reads or to over-complicate the code or even spending hours contemplating method and object names.
Too much Germane load makes learning a new task harder and slower.
Microservices have a handful of moving parts at the same time and more the moving parts, to begin with, the complicated it gets. Systematic tradeoffs need to be made by teams when building services. Teams have to communicate and learn from each other.
The Intrinsic load should reduce over time as new lower-level knowledge and experience are formed and documented.
Always try to complete that initial simple microservice end to end, and deploy it in production with a database, CICD, alert and monitoring system, testing strategies and version control in place. This makes the subsequent services to be carved out more easily. After a few services spinning up new services and it becomes a cakewalk.
As the experience increases handling cognitive load gets more mature and achievable.
Microservices in the last few years has become a hackneyed concept and the modus operandi methodology for building applications to drive digital transformations. The so-called adoption of modern Hydra with tentacles to replace the legacy one-eyed Cyclops seems what most organizations are striving towards when strategizing Modernization, Cloud adoption journeys or Agile and DevOps ways of working.
After spending few years learning and understanding the platform revamp of moving away from a bulky monolithic commerce platform to service-based architecture, I have learned myriad ways on how IT organizations bungle up a journey and at times come a whole full circle.
There is no direct method to this madness but for sure are best practices and learning from earlier blunders and possibilities to circumvent hidden trapsand pitfalls.
The Onset Enigma
The inception of the microservices journey is typically to combat the imponderable conundrums pertaining to “Slow time to market”, “Complex and heavily customized applications”, “Testing nightmares”, “Scalability and Stability issues”, “Velocity,” “Technology binding”, “Adopting modern stacks”, “Continuous Integration and Continuous Delivery”, “Cost factor” and locking vendor licensing model” and the list goes on.
Microservices approaches differ from organization to organization and there is no ready-made panacea. I have time and time seen teams perform a mere replication of these approaches resulting in incurring insurmountable technical debt.
Before embarking on a microservices journey, it’s essential to comprehend what issues one is trying to deal with and where one needs to start?
A lot of initial time has to be spent to understand the “complexities of the existing monolith”, “core issues with the legacy”, “technology forecast”, “business limitations”, “future business requirements”, “organization processes”, “their strengths and weaknesses, “team sizes”, “operational readiness” “ways of working” , “cultural standpoint”, “integration dependencies” and several other factors before choosing an approach.
It’s pretty common to see that modern IT teams yearn for re-architecting existing monolithic applications and move away from the mundane system to a more services-oriented modern stack and technology.
But, before even attempting the journey, teams need to evaluate if the journey is worth the endeavor? Typical questions teams need to ask themselves
Maybe the release cycles of the monolith are of way too less frequency and just leaving it alone is the best solution?
Maybe the monolith is of a specific size and estimated to not grow further?
Maybe the organization is not ready yet to begin the journey from an operational, technology, process or even from a cultural point of view?
Maybe there are way too many features in the monolith that is more crucial from a business and cost standpoint?
Maybe the monolith has a short lifespan and is getting replaced?
Maybe the organization is not yet agile or has not yet adopted DevOps which is pivotal for a microservices journey?
Maybe breaking the monolith is way too complex and it is easier to rewrite code from scratch using new software?
Maybe building new features is of more priority than breaking out new services?
Recently we have been observing that the website that I have been part of has been running on average constant response times for different peak loads. At this time, we had moved lot of the functionalities to different applications on the cloud where scalability is auto managed. This made us revisit the number of instances that we have been running in production on our on-premise servers. If these servers were required for the peak load and validate if we could save some money and maintenance on the infrastructure by reducing certain number of servers.
This required re calculating the capacity planning for different environments. To calculate the approximate capacity or how much traffic an application can hold up is based on different data points.
These datapoints include factors number of requests per second, average application server response times, number of instances and their details of CPU, cores, threads, sockets etc. All the required information typically can be gathered from the analytics tool like GA, or Adobe web analytics or monitoring tools like new relic, Dynatrace etc.
Calculating the number of Cores?
For doing this all we need is to load the cpu information (lscpu) and view the information related to Threads per socket, Cores per socket and number of Sockets. In the below case the number of core = 6 * 1* 1 = 6.
This value is for a specific instance or virtual machine and the total cores is calculated by adding all the virtual machine specific cores. For e.g. If there are 4 virtual machines then the total number of cores present in the infrastructure based on the above alogirthm is 4 * 6 = 24.
Calculate the maximum load or through put of the system?
The next step is to calculate the number of average requests to the application servers. This can be calculated by viewing the data of the monitoring tool. The information needs to be fetched for the most peak traffic or expected peak traffic for an application or website. For e.g. If the peak throughput for an application is say 1000 requests per minute. Then the value in RPS or request per second is 4000/60 = 66.66
Calculate the Average response times?
The next value that needs to be calculated is the average response times from the application server. This information also is available using any monitoring tool or can also be calculated by using the expected average value in seconds. For e.g. Assuming 250 m sec to be the average app server response time.
Now with the required information in place the number of cores can be calculated using the formulae
Number of cores = Requests per second * average response time in seconds
For.e.g Number of cores for peak traffic = 0.250 seconds * 66.66 = 16.665 cores. (app 17 Cores).
ØIf an application
migration requires lot of integration or coordination between internal and
external environments on top of the cloud services, it will become a layer
between the cloud provider and inhouse applications will struggle to keep up
with the rate of innovation in the cloud provider’s services. Cloud provides numerous
services that are portable. Organizations should not build or acquire layers of
insulation on top of cloud provider's native features in order to perceive portability.
ØModern cloud service providers can auto scale in order to create a resilient
and highly available applications. The cloud service providers have different
solutions to provide the ability to store and replicate data. If a legacy
application is critical enough to meet the requirement of fault tolerant, moving such applications to the cloud can be easier to manage.
ØCloud is a better fit if Speed and Agility are the primary business drivers
of an organization. In order to do so it is required for applications to have
continuous and direct access to the cloud provider's fast pace of innovation.
Only by building directly upon provider-native features will there be the
desired business agility and rate of improvement. Organizations will struggle to easily port applications across cloud
providers by sacrificing speed, agility and innovation.
ØAnother area to consider is the factor of repeatability for
applications. Typical scheduled deployment times in legacy application require a
down time along with human intervention in doing the same manual tasks repeatedly.
Also, in case of disaster recovery or outage most of the tasks carried out are
manual. Typical cloud services excel to execute the same tasks multiple times
without failure. Most of the application recovery or deployments are auto
managed and incur very little to no human interventions.
ØCloud services generally provides high flexibility and testability. Applications
can be tuned to run on need basis. Test environment application can be a good
candidate to move to the cloud especially when doing a load or stress testing. Different
applications can be made available on the fly based on different hardware
configuration, operating system and different regions and can be scaled up or
down on need basis. This gets even easier with cloud providers excelling in containerized
application and providing seamless continuous integration and deployment.
ØIf high performance, monitoring, volatility and high volume are the
key requirement then the application needs quick development and high rate of
innovation. Cloud vendors do provide ready-made
solutions to meet all such requirements. Performance benchmarks can be met with
different solutions that fulfil the key constraints of Caching, Sharding, Archiving
and Storage. Readymade tools can be configured to meet the requirement of in-depth
monitoring, logging and analysing. Cloud providers have rich support for
state-of-the art agile development modes including DevOps, containers,
microservices and will be the first to have mature support for upcoming methods
like serverless computing etc. Different pricing models and tenancy are also
provided that can ensure cost is kept to the minimum.
Every microservices journey is different for different organizations based on their core competency. However, few of the basic elements of where to start and where to end are more or less similar. Came across this below diagram on multiple websites which illustrates the typical migration model. Read only pages or static pages with content are much more easier to move to newer platforms especially on cloud services like SaaS than core business components.
ØElasticity is one of the major benefits of moving to the cloud. What
it essentially means is that the servers can be scaled in or out as needed.
While the cloud offers both horizontal and vertical scaling of applications, it’s
the horizontal scaling feature that reaps major benefits. If elasticity is the
not a key concern, then the application readiness for cloud needs to be
evaluated as it could be a better fit to be managed on premise or on a hosted
solution.
ØMost of the legacy application mainly scales vertically where the application
is dependent on core infrastructure and are tightly coupled with inhouse
hardware (low latency + high intensity, or high bandwidth) and specific software and technology stack. Moving such
applications to the cloud can create lot of complexities and can require lot of
rearchitecting. Also, moving such applications makes them look like a hosting
solution instead of a loosely coupled cloud solution.
ØModern cloud services rely mainly on databases which follow BASE properties,
(Basically available, soft state, eventual consistent transactions), and CAP theorem
(Consistency, Availability and Partition Tolerant) i.e. if the transactions
fail the data will become eventual consistent. Legacy applications are
typically monolithic, and the underlying data is mainly designed for ACID
transactions, (Atomicity, consistency, isolation, and durability), i.e.
transactions are not complete until the data is committed. Applications can get
complex to function in the cloud and make use of core cloud features if they
are not capable of meeting the goal of eventual consistency and Partition
tolerant.
ØWhen moving application to the cloud another property that needs to
be evaluated is the aspect of application state. Cloud is suited well for an
application that is stateless, i.e. when the client is unaware of the state of
the server. Stateless applications are also easier to size and cache on the
cloud. If the legacy application is stateful, i.e. the application has lot of dependency
on infrastructure. It will get complex moving them to cloud considering the
different requirements around sizing, capacity planning, caching etc.
ØIf applications require lot of security and compliance, the
organizations also share responsibility with the cloud vendor for lot of IT management
if they are moved to the cloud. Organization not only need to maintain adequate
governance but also are responsible for meeting the required compliance and
audit standards. While most of the major cloud vendors do provide increase IT security including
Intrusion Prevention Systems, Web application firewalls, Runtime application self-protection,
converged application performance and security monitoring, botnet and DDoS mitigation
mechanisms to meet the regulatory standards. Moving
such applications to cloud can be more of a hassle in terms of management,
quality adherence, maintenance etc than keeping them inhouse.
ØConnectivity and Interoperability
is another key consideration when deciding to move applications
to the cloud. Every major cloud provider does have the ability to either
connect directly or via a virtual private network. But this requires organization
to cover up all the critical loopholes for such connections in the targeted and
dependent applications. This can be a very tedious task and can lead to several
challenges if the organization is not ready.